Google is Developing a Photo Recognition Program That Can Describe Exactly What’s in Your Photos

Scientists at Google Research and Stanford University have teamed up to develop an artificial intelligence program designed to automatically produce captions based on the content of the image.
That’s right, not just tags, full on captions like “A person riding a motorcycle on a dirt road.”
The entire process is complicated one to say the least, but the basic premise behind the machine-learning system is that there are two synchronized neural networks: one for breaking apart the image pixel-by-pixel, and another for sorting through language to intelligently produce a description of the scene.
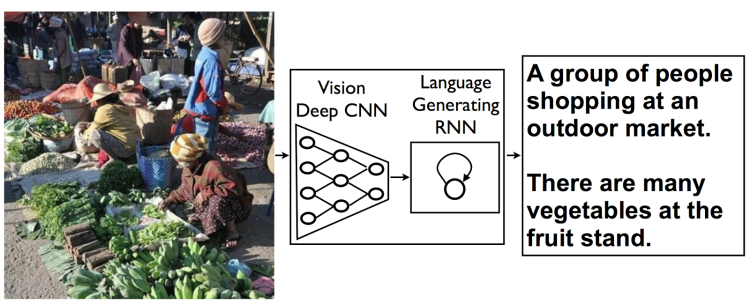
Using this connected network of artificial intelligence, scientists say they can ‘teach’ the program to properly recognize what’s in your photos by introducing images that are already captioned.
Using the descriptions given by researchers in the already-captioned images, the program then parses through and stores that data for use in future images.
The system is far more intelligent than a simple tagging system. It not only picks up on the details, like a color or object, but also understands the scene in context. In other words: it can not only understanding that a photo has ‘snow’ and ‘trees’ in it, the program could tell you that, “the snow is falling in front of the line of trees.”

This contextualization of language is not only impressive (when it works), but is also capable of parsing through images almost twice as fast as any previous technology. The problem, as you might imagine, is that it’s still in its infancy.
While it can nail the caption some of the time, the data set is still small and without many more ‘training’ images from humans, the program can easily go astray. But as larger amounts of data are entered and the AI gets more and more intelligent, the technology is bound to improve.
It’s not likely we’ll be seeing this technology for years to come, but someday, your Lightroom library might be able to caption itself from start to finish…
(via Engadget)