The Limits of ‘Computational Photography’

My name is Will Yager, and I’m a software engineer. I was recently discussing laser etching with an engineer/font-designer friend of mine, and I wanted to show him a picture of some really good laser etching on a particular piece of optical equipment.
Every time I tried to take a picture of the engraved text, the picture on my phone looked terrible! It looked like someone had sloppily drawn the text with a paint marker. What was going on? Was my vision somehow faulty, failing to see the rough edges and sloppy linework that my iPhone seemed to be picking up?
No, in fact – when I took the same picture using a “real” camera, it looked exactly as I expected!

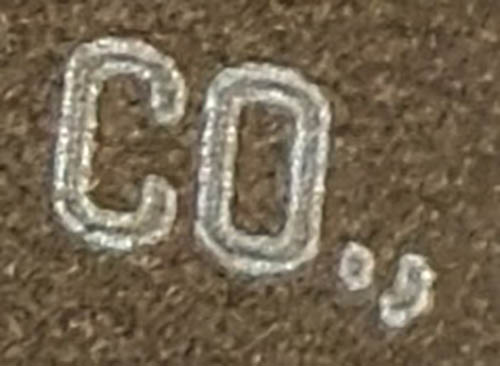
What is going on here? Well, I noticed that when I first take the picture on my iPhone, for a split second the image looks fine. Then, after some processing completes, it’s replaced with the absolute garbage you see here. Something in the iPhone’s image processing pipeline is taking a perfectly intelligible and representative (if perhaps slightly blurry) image and replacing it with an “improved” image that looks like crap.
Computational Photography as a Marketing Tool
For the last few decades, smartphones have been gradually eating into the dedicated camera market. Most people only benefit from very basic photographic functionality (taking some baby pictures, making a copy of a receipt, etc.). There’s basically zero market for “casual” dedicated cameras anymore; basically anyone who has a dedicated camera today is relatively serious about it, either because they’re using their camera in a professional capacity or pushing the limits of the camera beyond what cell phone cameras can handle.
Of course, as a matter of pride and marketing, it’s important for cell phone manufacturers to try to demonstrate (at least to casual consumers) that they can compete with “serious” dedicated cameras (including by resorting to dubiously-truthful advertising strategies like the misleading “Shot on iPhone” campaign, or disreputable Android phone manufacturers using sneaky tricks to make certain subjects look better).
Why is it that people who are serious about quality still use dedicated cameras? Are dedicated cameras really fundamentally better than cell phone cameras, or are photographers just being stodgy and old-fashioned?
The answer, as you might be able to guess from Apple’s (apparent) best effort to take a picture of my gizmo, is “yes, dedicated cameras have some significant advantages”. Primarily, the relevant metric is what I call “photographic bandwidth” – the information-theoretic limit on the amount of optical data that can be absorbed by the camera under given photographic conditions (ambient light, exposure time, etc.).
Cell phone cameras only get a fraction of the photographic bandwidth that dedicated cameras get, mostly due to size constraints. A non-exhaustive list of factors that allow dedicated cameras to capture more optical data:
Objective Lens Diameter
The size of the objective (the dark part you see in the center of the camera lens) determines how much light gets into the camera. If your objective lens is tiny (as is the case on most cell phone cameras), you can’t really collect that much light. Fewer photons means less optical data means a lower ceiling on image quality, especially in dimmer environments.
While not strictly related to image bandwidth, it’s worth noting that having a larger objective lens also allows you to achieve the desired “bokeh” effect, where the background is smoothly blurred out while the subject is in focus. Modern cell phones typically have a mode to (poorly) emulate this blurring.
Optical Path Quality
Photons have to travel from the objective lens to the sensor, and there are several (bad) things that can happen to them on the way.
One constraint is the diffraction limit. When you have a small aperture (related to, but not precisely the same as, the objective diameter), it causes the incoming photons to refract slightly, causing blurring in the image. This blurring reduces photographic bandwidth, because adjacent pixels become correlated, reducing the maximum entropy of the image. Cell phone apertures are small enough that this is a concern. Why don’t they just make the apertures bigger? Well, because you’d have to make the lens longer too, and your cell phone would be way too thick.
A second constraint is aberration, which is error introduced by the lens itself. For example, chromatic aberration: if you have to make a lens for a single frequency of light, it’s pretty easy. You can calculate the optimal lens shape based on the index of refraction of the glass you’re using, grind it out, and you’re good to go. Unfortunately, the index of refraction of glass actually depends on the color of the light going through it, so a lens that’s perfect for 650nm red light will not be perfect for 450nm blue light. Lens designers correct for this by using multiple stacked lens elements, so the aberration introduced by one lens element will be (partially) counteracted by aberration from another lens element.
Because cell phone optics designers are extremely size-constrained, they have to focus on things like making the flattest lens possible rather than minimizing aberration. Dedicated camera manufacturers have much more freedom to focus on lens quality over lens size.
Pixel Size and Sensor Depth
In order to fit inside a cell phone, and because of the small lenses involved, cell phone camera sensors are very tiny compared to dedicated camera sensors.
The biggest sensor in an iPhone is 9.8×7.3mm, whereas a full-frame sensor (common enough in pro and prosumer cameras) is 24x36mm – over 12 times larger!
This matters for a couple of reasons. First is that smaller pixels are more sensitive to absolute errors introduced by the optics. If something is 1 micrometer off, that’s a bigger deal if each pixel is only ~1um wide (as in an iPhone camera) vs ~4um wide (as in a dedicated camera).
Second, and perhaps more importantly, is that the larger sensor can count more photons per pixel. Technically this is not directly related to the area of the sensor, but given current manufacturing and process constraints, they end up being related. Let’s say an iPhone pixel has an area of 1x1um, vs 4x4um in a dedicated camera. Each pixel has a capacitor, which is used to store electrons generated by photon impacts. A larger pixel has more “storage space” for electrons. If the relationship is linear with area, the dedicated sensor can store 16x as many electrons before maxing out. Let’s say the dedicated sensor can store 64k electrons (representing 64k absorbed photons per pixel) vs only 4k on the iPhone.
Photon arrival is a poisson process. Let’s assume that the photograph we’re taking is well-exposed, and the average pixel value is half of the maximum. The inherent physical poisson noise on the dedicated sensor will have a standard deviation of √32000 ≈ 180, leading to an SNR of 32000/180 ≈ 180 ≈ 27.5. Therefore, we might hand-wavily say that the “useful bandwidth” of each pixel is around 7.5 bits per exposure.
On the other hand, the iPhone sensor in the same situation would have an SNR of 2000/√2000 ≈ 45 ≈ 25.5. The “useful bandwidth” of each pixel per exposure is about 2 bits per pixel higher on the dedicated camera.
Note: For a much more detailed article on SNR and poisson processes and so on, check out my article “Intro to Computational Astrophotography“.
There are various ways to speak and reason about this phenomenon, including in terms of “dynamic range”, but I think the number-of-electrons explanation is the most helpful.
Can Computational Photography Help?


The promise of “computational photography” is that we can overcome these physical constraints using the power of “smart” algorithms. How well does this actually work?
There are different types of “computational photography”, some more or less sane than others. The least objectionable instances are things like software chromatic aberration correction, where we try to correct for predictable optical path errors in software. I like to think of optical path errors as belonging to several categories:
- “Injective” errors. Errors where photons end up in the “wrong” place on the sensor, but they don’t necessarily clobber each other. E.g. if our lens causes the red light to end up slightly further out from the center than it should, we can correct for that by moving red light closer to the center in the processed photograph. Some fraction of chromatic aberration is like this, and we can remove a bit of chromatic error by re-shaping the sampled red, green, and blue images. Lenses also tend to have geometric distortions which warp the image towards the edges – we can un-warp them in software. Computational photography can actually help a fair bit here.
- “Informational” errors. Errors where we lose some information, but in a non-geometrically-complicated way. For example, lenses tend to exhibit vignetting effects, where the image is darker towards the edges of the lens. Computational photography can’t recover the information lost here, but it can help with basic touch-ups like brightening the darkened edges of the image.
- “Non-injective” errors. Errors where photons actually end up clobbering pixels they shouldn’t, such as coma. Computational photography can try to fight errors like this using processes like deconvolution, but it tends to not work very well.
Slightly more objectionable, but still mostly reasonable, examples of computational photography are those which try to make more creative use of available information. For example, by stitching together multiple dark images to try to make a brighter one. (Dedicated cameras tend to have better-quality but conceptually similar options like long exposures with physical IS.) However, we are starting to introduce the core sin of modern computational photography: imposing a prior on the image contents. In particular, when we do something like stitch multiple images together, we are making an assumption: the contents of the image have moved only in a predictable way in between frames. If you’re taking a picture of a dark subject that is also moving multiple pixels per frame, the camera can’t just straightforwardly stitch the photos together – it has to either make some assumptions about what the subject is doing or accept a blurry image.
Significantly more objectionable are the types of approaches that impose a complex prior on the contents of the image. This is the type of process that produces the trash-tier results you see in my example photos. Basically, the image processing software has some kind of internal model that encodes what it “expects” to see in photos. This model could be very explicit, like the fake moon thing, an “embodied” model that makes relatively simple assumptions (e.g. about the physical dynamics of objects in the image), or a model with a very complex implicit prior, such as a neural network trained on image upscaling. In any case, the camera is just guessing what’s in your image. If your image is “out-of-band”, that is, not something the software is trained to guess, any attempts to computationally “improve” your image are just going to royally trash it up.
Ultimately, we are still beholden to the pigeonhole principle, and we cannot create information out of thin air.
About the author: Will Yager is a software and hardware engineer. You can find more of his work and writing on his website and Github. This article was also published here.


