A Deeper Look at the Technology Driving Google’s New Personal Photo Search
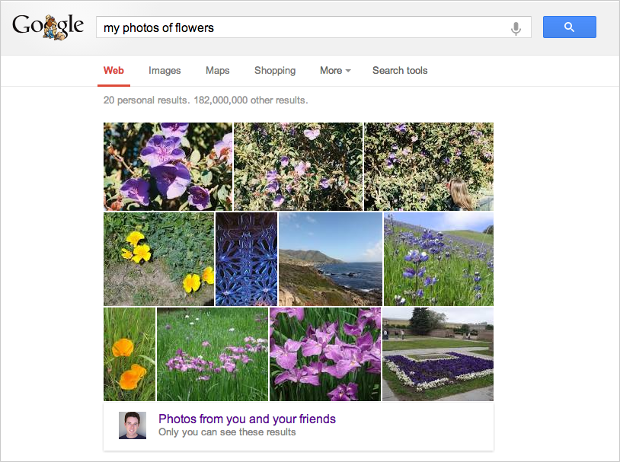
Right after Google I/O wrapped up in May, we shared the news that Google’s personal image search had just gotten a whole lot better. The tech giant claimed that you could now search through yours and your friends photos based on visual content, even if the photos themselves weren’t labeled or tagged.
At the time, all we knew was that the system used “computer vision and machine learning” to detect subjects like “flowers,” “food” or “car” and generate searchable tag data that makes your photos easier to find. Now, thanks to Google’s Research blog, we’re getting a bit more detail on the tech under the hood.
The full post is quite lengthy and full of technical details the likes of which we won’t try to get into here, but there were a few things that stood out. For one, it’s impressive just how quickly Google brought this technology out of the research lab and into the real world.
It took only six months from the moment Professor Geoffrey Hinton’s team at the University of Toronto won the ImageNet computer vision competition using their newly created system, to when Google launched their version to the public. Now, they’re running a system that can recognize, for example, that the photo below contains flowers:

The tech behind that recognition is no less impressive than Google’s speed, but a bit harder to explain. The system uses what’s called “deep learning” and “convolutional neural networks.” Convolutional neural networks have been around since the 90s, but the advancement of technology over time (both in terms of speed and capacity) has allowed the systems to run more complex algorithms on more data:
Bigger and faster computers have made it feasible to train larger neural networks with much larger data. Ten years ago, running neural networks of this complexity would have been a momentous task even on a single image — now we are able to run them on billions of images. Second, new training techniques have made it possible to train the large deep neural networks necessary for successful image recognition.
From training the system to running actual tests, the Google team was usually impressed with what it was capable of during development. With the exception of some reasonable errors that any human might make when looking at a photo (for instance, mistaking a millipede for a snake) the system could handle both abstract and specific classes of data well.

For example, it can tell that the photo above contains, not just a bear, but a polar bear. It can also distinguish photos of abstract concepts like “meal” fairly well (bringing up photos of diner tables and food), and make generalizations about things like cars, recognizing both the interior and exterior of a vehicle as a “car.”
It may seem small, but in Google’s own words, the most advanced computers running the best algorithms would still lose to a toddler when it comes to identifying what’s in a photo … until now. Now, this system has moved things “a bit closer to toddler performance.”
To find out more about the digital brain working to help you dig up long-lost photos that you never thought to tag, head over to the Google Research blog and read up on all the technical details.
Improving Photo Search: A Step Across the Semantic Gap [Google Research Blog]
Image credit: Flowers by TalAtlas and Polar Bear by ST33VO


