‘Multimodal AI’ Is Everywhere and How Companies Make AI More Human

“Multimodal AI” is suddenly everywhere, with companies like Meta, OpenAI, Google, and Microsoft all using the term to sell people on new AI models and services in just the past few weeks. But what is “multimodal,” and what does it mean?
The idea of multimodality is not new, even if it has suddenly entered the technological cultural zeitgeist. People have learned about the world through multimodality since the dawn of humanity, and it’s not limited to humans, either. At its most basic level, multimodality is the idea that individuals learn about their surroundings through multiple senses or processes.
For example, communication between two people is multimodal because people use text, voice, facial expressions, body language, and even photos, videos, and drawings.
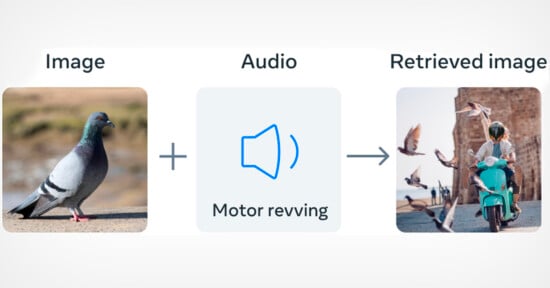
“It is very safe to assume that future communication between human and machine will also be multimodal,” says Jina AI’s CEO Han Xiao in an article on MIT Technology Review.
It’s safe to assume, indeed, as that’s precisely how other AI companies say they are approaching the technology right now.
For example, in OpenAI’s new GPT-4o, a user can interact with AI through text, audio, and images, all processed simultaneously.
“The Gemini model family includes models that work with multimodal prompt requests. The term multimodal indicates that you can use more than one modality, or type of input, in a prompt. Models that aren’t multimodal accept prompts only with text. Modalities can include text, audio, video, and more,” Google explains in a guide to its Gemini AI models.
Meta says something similar, writing that multimodal AI systems “accept multiple types of inputs, such as text and images, and produce various forms of output.”
“In the realm of AI, the new frontier isn’t confined to a singular form of expression; fast-paced developments are happening at the juncture of multiple modalities. Multimodal AI systems that can analyze, synthesize, and generate across text, images, and other data types are paving the way for exciting applications in areas such as productivity, health care, creativity, and automation,” Microsoft explained in a paper on responsible multimodaL AI development published last year. “As human perception and problem-solving in the physical world leverage multiple modalities, such multimodal systems provide an even more natural and seamless support than those operating across a single modality.”
Per MIT, even still, this comes up a bit short of a true multimodal AI system, as contemporary approaches still rely on some form of model fusion to handle different types of inputs and outputs. Pulling the threads apart and seeing what’s happening under the hood can be difficult.
For its part, OpenAI’s CEO Sam Altman claims GPT-4o is “natively multimodal,” which suggests, if not outright states, that the company’s latest GPT model is not relying on the same fusion as GPT-4 did.
In any event, “multimodal” will be the AI buzzword of 2024. So far this month, Meta, OpenAI, Google, and Microsoft have used the term so many times that it could make someone’s head spin.
Popular tech YouTuber Marques Brownlee saw this coming. In his 2024 tech prediction video earlier this year, Brownlee dedicated a section to “multimodal AI,” saying 2024 would be the year for “multimodal AI.” So far, he’s right on the money.
Speaking of money, there is much to be made on the backs of multimodal AI products and services, per MIT Technology Review. In the publication’s full report, it says the global multimodal AI market is expected to grow “at an annual average rate of 32.2% between 2019 and 2030,” reaching a market value of $8.4 billion by 2030.
“There is no doubt that any chief digital transformation officers or chief AI officers worth their salt will be aware of multimodal AI and are going to be thinking very carefully about what it can do for them,” says Henry Ajder, founder of Latent Space.
“Multimodal has clear benefits and advantages, but there’s no sugarcoating the complexities it brings,” adds Ajder. These complexities include significant challenges with training multimodal models. Further, some issues with unimodal AI, like dangers and biases, are only exacerbated by the move to a multimodal AI platform.
Given that it’s far from settled that AI companies have overcome these ethical and pragmatic hurdles with relatively simple, albeit still complex, unimodal AI tools, the rapidity with which these companies are developing and launching multimodal AI gives some experts pause.
“Despite the uncertainties, however, many companies will likely have no choice but to face the potential risks of multimodal AI, given the opportunities it can herald,” MIT Technology Review concludes.
Image credits: Featured image by Microsoft