OpenAI Announces GPT-4o: A ‘Real-Time’ Multi-Modal AI

OpenAI today released GPT-4o, the company’s new flagship AI model. The “o” stands for “omni,” and reflects GPT-4o’s ability to handle multiple types of inputs at once, including audio, images, and text.
This multimodal AI model also promises significant performance and speed improvements, improved ease of use, and more functionality. OpenAI’s big announcement arrives just 24 hours before Google’s I/O 2024 developer conference kicks off in California. Given OpenAI’s significant support from Google competitor, Microsoft, this is undoubtedly not a coincidence.
GPT-4o can respond to audio inputs in as little as 232 milliseconds, per OpenAI, which the company notes is “similar to human response time.” The new model also matches GPT-4 Turbo performance on English text and code while offering “significant improvement” with text in non-English languages. It is also 50% cheaper in the API. Concerning “vision” and audio understanding, the tech company says GPT-4o is “especially better.”

One of the most significant changes is that GPT-4o processes multiple types of inputs and outputs using the same neural network. This is in stark contrast to GPT-3.5 and GPT-4, which used numerous models to transcribe audio to text, analyze the text, and output it back as audio. OpenAI says this approach “loses a lot of information,” and its older models struggled to interpret tone and handle multiple speakers.
GPT-4 also can’t output “laughter, singing, or express emotion,” although genuine laughter and emotion remain far outside the reach of any AI model, even if GPT-4o can make laughing sounds and tell a user who sounds stressed to calm down.
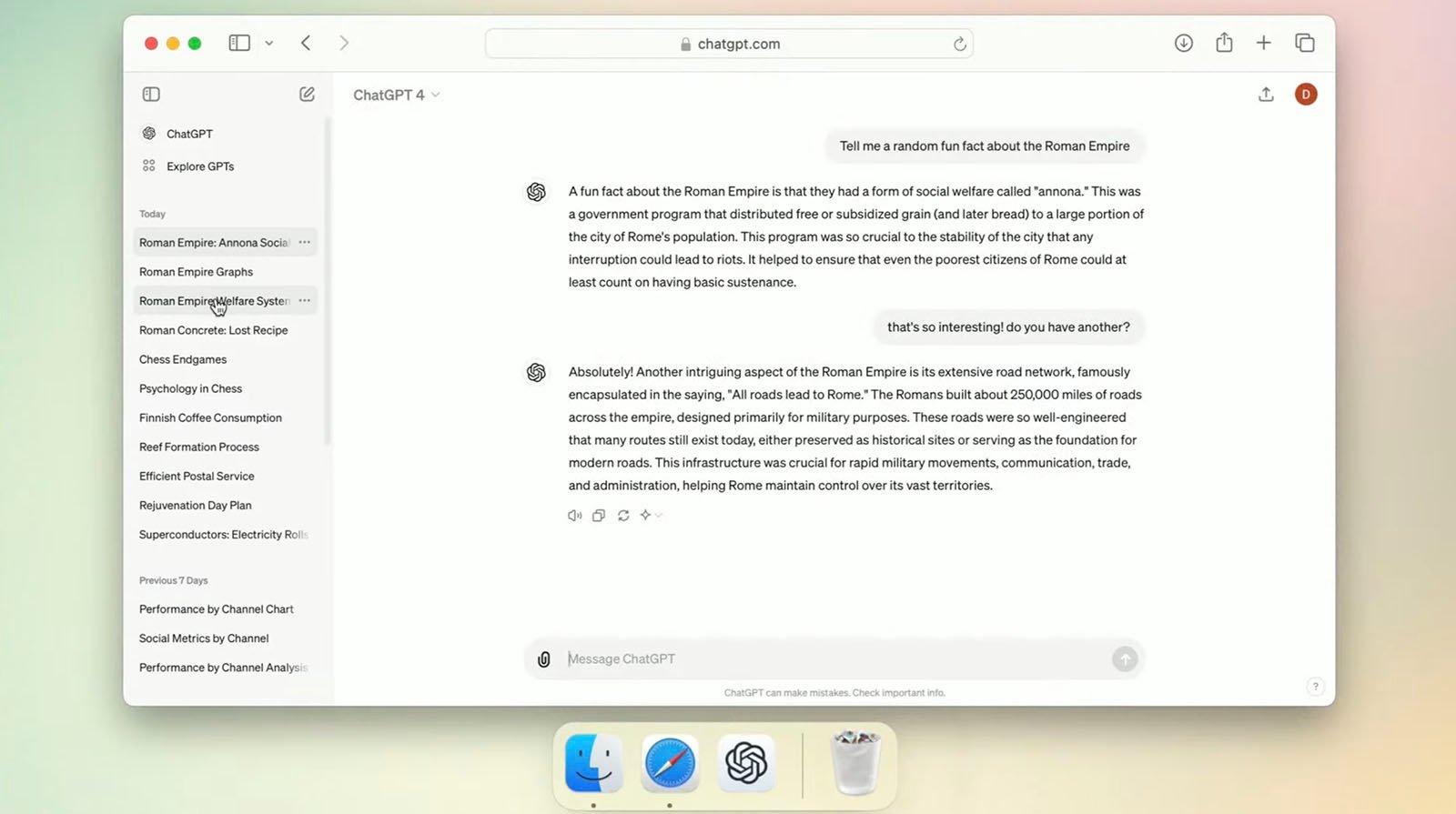
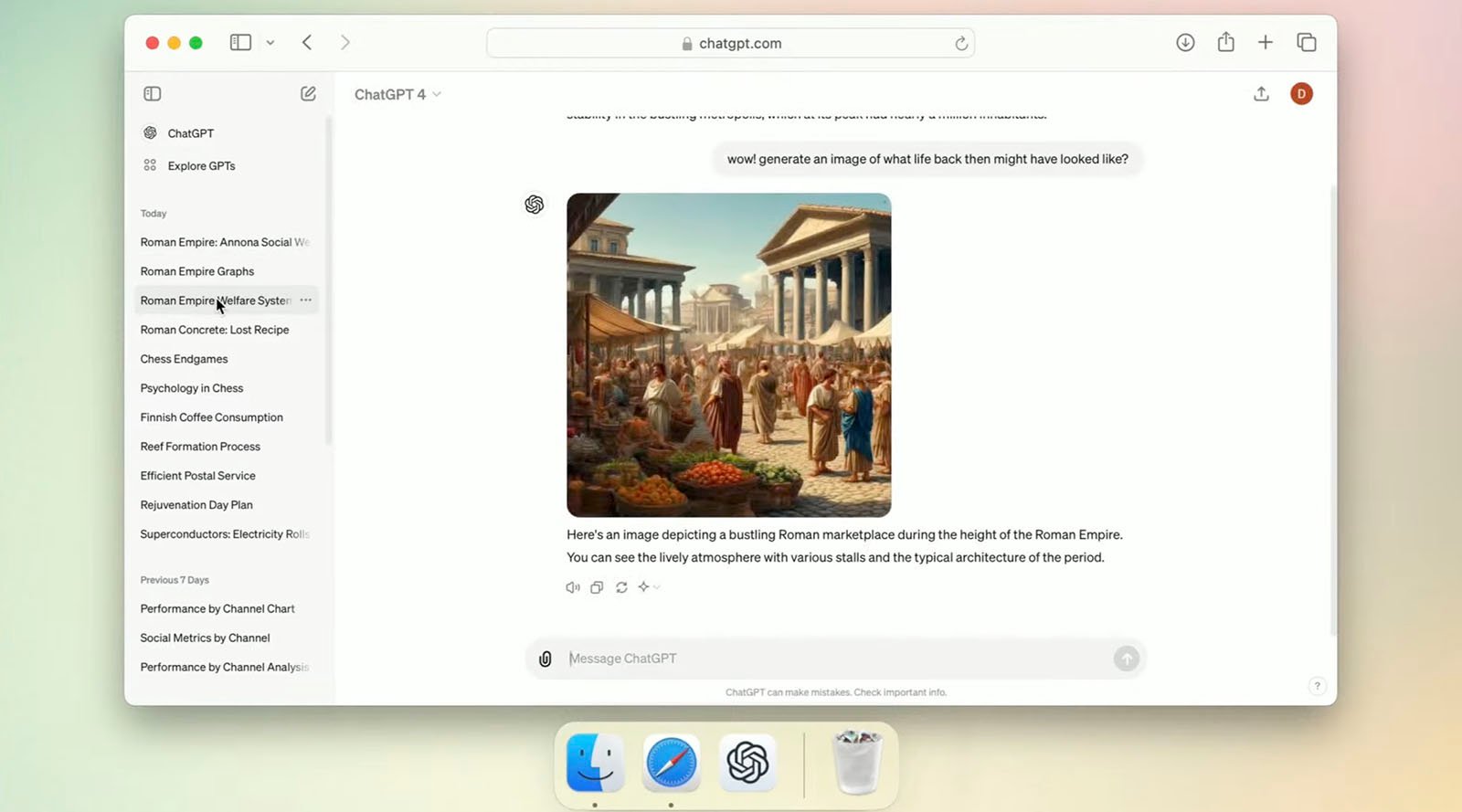
Given GPT-4o’s multimodal capabilities, OpenAI is clearly aiming to make ChatGPT a proper AI assistant. Since GPT-4o can engage in real-time conversations and interact with text and images, the AI can talk to a person about a wide range of uploaded media.
“Our new model: GPT-4o, is our best model ever. It is smart, it is fast, it is natively multimodal, and it is available to all ChatGPT users, including on the free plan!” OpenAI CEO Sam Altman writes on X. “So far, GPT-4 class models have only been available to people who pay a monthly subscription. This is important to our mission; we want to put great AI tools in the hands of everyone.”
Microsoft has invested heavily in OpenAI and it is expected that the company’s technology will find its way into Microsoft products in relatively short order. And no, OpenAI still isn’t saying how it trained its Sora video generator.
OpenAI will launch ChatGPT on desktop later this year, complete with the new GPT-4o capabilities. These capabilities are rolling out now to select ChatGPT users and will soon be available to more users. ChatGPT is also getting a streamlined user interface to take full advantage of these new capabilities and be more accessible to a broader user base.
Image credits: OpenAI


