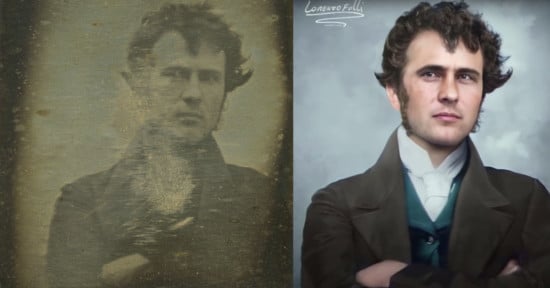A (Very) Technical Look at Creating an AI to Restore and Colorize Photos

In this article, I’m going to tell a story of how we’ve created AI-based restoration project for old military photos.
What is “photo restoration”? It consists of three steps:
1. We find all the image defects: fractures, scuffs, holes;
2. We inpaint the discovered defects, based on the pixel values around them;
3. We colorize the image.
Further, I’ll describe every step of photo restoration and tell you how we got our data, what nets we trained, what we accomplished, and what mistakes we made.
Looking for Defects
We want to find all the pixels related to defects in an uploaded photo. First, we need to figure out what kind of pictures will people upload. We talked to the founders of “Immortal Regiment” project, a non-commercial organization storing the legacy photos of WW2, who shared their data with us. Upon analyzing it, we noticed that people upload mostly individual or group portraits with a moderate to a large number of defects.
Then we had to collect a training set. The training set for a segmentation task is an image and a mask where all the defects are marked. The easiest way to do it is to let the assessors create the segmentation masks. Of course, people know very well how to find defects, but that would take too long.

It can take one hour or the whole workday to mark the defect pixels in one photo. Therefore, it’s not easy to collect a training set of more than 100 images in a few weeks. That’s why we tried to augment our data and created our own defects: we’d take a good photo, add defects using random walks on the image, and end up with a mask showing the image parts with the defects. Without augmentations, we’ve got 68 manually labeled photos in training set and 11 photos in the validation set.
The most popular segmentation approach: take Unet with pre-trained encoder and minimize the sum of BCE (binary cross-entropy) and DICE (Sørensen–Dice coefficient).
What problems arise when we use this segmentation approach for our task?
1. Even if it looks like there are tons of defects in the photo, that it’s very old and shabby, the area with defects is still much smaller than the undamaged one. To solve this issue, we can increase the positive class weight in BCE; an optimal weight would be the ratio of clean pixels to defective ones.
2. The second problem is that if we use an out-of-box Unet with pre-trained encoder (Albunet-18, for example), we lose lots of positional data. The first layer of Albunet-18 consists of a convolution with a kernel 5 and a stride that equals two. It allows the net to work fast. We traded-off the net operation time to have better defects localization: we removed max pooling after the first layer, decreased stride to 1 and decreased the convolution kernel to 3.
3. If we work with small images by compressing them, for example, to 256 x 256 or 512 x 512 pixels, then small defects will disappear due to interpolation. Therefore, we need to work with larger images. We are currently segmenting defects in 1024 x 1024 sized photos in production. That’s why we had to train the net on big image crops. However, this causes problems with a small batch size on a single GPU.
4. During the training, we can fit about 20 images on one GPU. Because of that, we end up with inaccurate mean and standard deviation values in BatchNorm layers. We can solve this problem using In-place BatchNorm, that, on the one hand, saves the memory space, and on the other hand, has a Synchronized BatchNorm version, that synchronizes statistics across all GPUs. Now we calculate the mean and standard deviation values not for 20 images on a single GPU, but for 80 images from 4 GPUs. This improves the net convergence.
Finally, upon increasing BCE weight, changing architecture, and using In-place BatchNorm, we made the segmentation better. However, it wouldn’t cost too much to do something even better by adding Test Time Augmentation. We can run the net once on an input picture, then mirror it and rerun the net to find all the small defects.

The net converges in 18 hours on four GeForce 1080Ti. Inference takes 290 ms. It’s quite long, but that’s the price of our better-than-default performance. Validation DICE equals 0,35, and ROCAUC — 0,93.
Image Inpainting
Same with the segmentation task we used Unet. To do inpainting we’d upload an original image and a mask where we marked all the clean area with ones, and with zeros – all the pixels we want to inpaint. This is how we were collecting data: for any photo from an open-source image dataset, for example, OpenImagesV4, we add the defects similar to those we see in real life. Then we’d trained the net to restore the missing parts.
How can we modify Unet for this task?
We can use partial convolution instead of an original one. The idea is that when we convolve an area with some kernel, we don’t take the defect pixels values into account. This makes the inpainting more precise. We show you an example from the recent NVIDIA paper. They used Unet with a default 2-dimensional convolution in the middle picture and a partial convolution – in the picture on the right.

We trained the net for five days. On the last day, we froze BatchNorms to make the borders of the painted part less visible.
It takes the net 50 ms to process one 512 x 512 picture. Validation PSNR equals 26,4. However, you can’t totally rely on the metrics in this task. To choose the best model, we run several good models on valuation images, anonymized the results, and then voted for the ones we liked the most. That’s how we picked our final model.
I’ve mentioned earlier that we artificially added some defects to the clean images. You should always track the maximum size of added defects during training; in a case when you feed an image with a very large defect to the net it’s never dealt with at training stage, the net will run wild and produce an inapplicable result. Therefore, if you need to fix large defects, augment your training set with them.
Here is the example of how our algorithm works:

Colorization
We segmented the defects and inpainted them; the third step – color reconstruction. Like I said before, there are lots of individual and group portraits among Immortal Regiment photos. We wanted our net to work well with them. We decided to come up with our own colorization since none of the existing services could color the portraits quickly and efficiently. We want our colorized photos to be more believable.

GitHub has a popular repository for photo colorization. It does a good job but still has some issues. For example, it tends to paint clothes blue. That’s why we rejected it as well.
So, we decided to create an algorithm for image colorization. The most obvious idea: take a black-and-white image and predict three channels: red, green, and blue. However, we can make our job easier: work not with RGB color representation, but with YCbCr color representation. Y component is brightness (luma). An uploaded black-and-white image is Y channel, and we are going to reuse it. Now we need to predict Cb and Cr: Cb is the difference of blue color and brightness and Cr – the difference of red color and brightness.

Why did we choose YCbCr representation? A human eye is more sensitive changes in brightness than to color changes. That’s why we reuse Y component (brightness) which a human eye is most sensitive to and predict Cb and Cr that we might make a mistake with since we can’t notice color falsity very well. This specific characteristic was widely used at the dawn of color television when channel capacity wasn’t enough to transmit all the colors. The picture was transmitted in YCbCr, unchanged to the Y component, and Cb and Cr were reduced by half.
How to Create a Baseline
We can take Unet with a pretrained encoder and minimize L1 Loss between the existing CbCr values and predicted ones. We want to color portraits and, therefore, besides OpenImages photos, we need more task-specific photos.
Where can we get colorized photos of people dressed in a military uniform? There are people on the internet who colorize old photos as a hobby or for a price. They do it very carefully, trying to be very precise. When they color a uniform, shoulder boards, and medals, they refer to the archive materials, so the results of their work are trustworthy. All in all, we used 200 manually colorized pictures with people in military uniform on them.
The other useful data source is The Workers’ and Peasants’ Red Army website. One of its founders had his picture taken in pretty much every World War 2 Soviet uniform available.

In some pictures, he imitated the poses of people from the famous archive photos. It’s a good thing that his pictures have white background: it allowed us to augment the data very well by adding various natural objects in the background. We also used some regular portraits, supplementing them with insignias and other wartime attributes.
We trained AlbuNet-50 – it’s a Unet that uses pretrained ResNet-50 as an encoder. The net started to give adequate results: the skin was pink, the eyes – gray-blue, the shoulder boards – yellowish. However, the problem was that it leaves some areas on photo untouched. This was caused by the fact that according to error L1 find such optimum where it’s better to do nothing than trying to predict some color.

How can we solve this problem? We need a discriminator: a neural network that would receive an image and tell us whether it looks realistic or not. One of the pictures below is colored manually and the other – by our generator, AlbuNet-50. How does human distinguish manually and automatically colored photos? By looking at details. Can you tell where the automatically colorized photo by our baseline solution is?

We use the discriminator from the Self-Attention GAN paper. It’s a small convolution net with so-called Self-Attention built in the top layers. It allows us to “pay more attention” to the image details. We also use spectral normalization. You can find more information in the abovementioned paper. We’ve trained the net with a combination of L1 loss and a loss from the discriminator. Now the net colorizes the image details better, and the background looks more consistent. One more example: on the left is the work by net trained with L1 loss only; on the right – with a combination of L1 discriminator losses.

Training process took two days on four GeForce 1080Ti. It takes the net 30 ms to process a 512 x 512 picture. Validation MSE – 34.4. Just like with inpainting, metrics you don’t want to rely on metrics. That’s why we picked six models with the best validation metrics and blindly voted for the best model.
When we’ve already created a production system and launched a website we continued experimenting and concluded that we better minimize not per-pixel L1 loss, but perceptual loss. To calculate it, we feed the net predictions and a ground-truthl photo to VGG-16 net, take the feature maps on the bottom layers and compare them with MSE. This approach paints more areas and gives more colorful results.

Recap
Unet is a pretty cool model. At the first segmentation task, we faced a problem during the training, and work with high-resolution images and that’s why we use In-Place BatchNorm. At our second task (Inpainting) we used Partial Convolution instead of a default one, and it allowed us to get better results. When working on colorization, we added a small discriminator net which penalized the generator for unrealistic images. We also used a perceptual loss.
Second conclusion – assessors are essential. And not only during the creating segmentation masks stage but also for the final result validation. In the end, we give user three photos: an original image with inpainted defects, a colorized photo with inpainted defects and a simply colorized one in case the algorithm for defect search and inpainting got it wrong.
We took some pictures from the War Album project and processed them over these neuronets. Here are the results we got:

Moreover, here you can take a closer look at the original images and all the processing stages.
About the author: Fedor Kitashov is a research engineer at the Mail.ru Group computer vision team. The opinions expressed in this article are solely those of the author. Kitashov graduated with a bachelor’s degree in applied mathematics and physics from Moscow Institute of Physics and Technology. Areas of interest include computer graphics, conversational agents, high-load systems. Kitashov worked as a research intern at CERN, Switzerland, Cisco, California, Kaspersky Lab, Russia. This article was also published here.