Meta Trained its New AI Using Public Instagram and Facebook Posts

This week, Meta unveiled a host of new AI-powered features that would soon roll out to its products and services. One new addition is Meta AI, a virtual assistant that will soon live on its apps and was trained using Instagram and Facebook posts.
Over the last year, new AI-based tools have become ubiquitous in tech culture. It seems that almost every new software feature or product needs to have something “AI” in it, and Meta — which pivoted from focusing heavily on the metaverse to AI once it became clear that the virtual world Zuckerberg envisioned was not popular — is no exception.
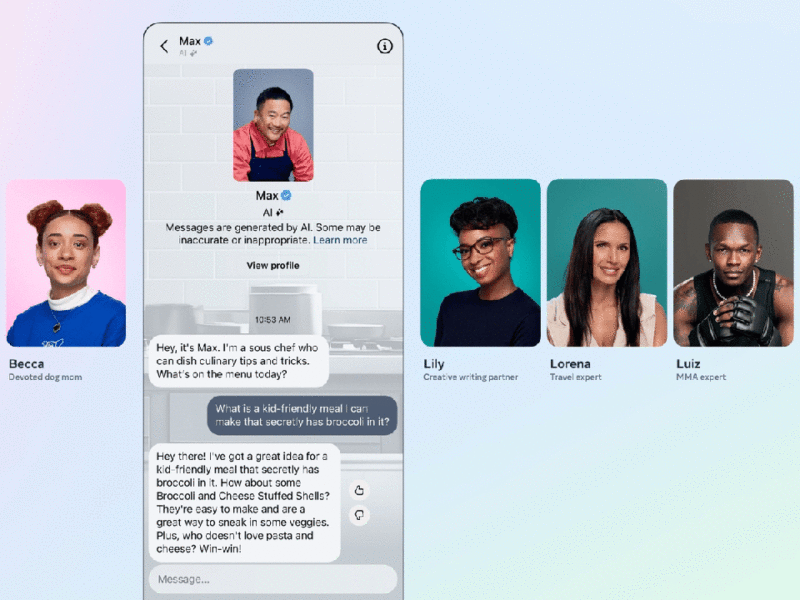
On Thursday, Meta announced a suite of new AI features that range from editing tools in Instagram to a new AI assistant named Meta AI.
“Meta AI is a new assistant you can interact with like a person, available on WhatsApp, Messenger, Instagram, and coming soon to Ray-Ban Meta smart glasses and Quest 3,” Meta explains in a public press statement.
“It’s powered by a custom model that leverages technology from Llama 2 and our latest large language model (LLM) research. In text-based chats, Meta AI has access to real-time information through our search partnership with Bing and offers a tool for image generation.”
Apparently that’s not the whole story, as Meta also used public Facebook and Instagram posts to train parts of the AI, according to Meta President of Global Affairs Nick Clegg, speaking to Reuters.
“We’ve tried to exclude datasets that have a heavy preponderance of personal information,” Clegg tells the publication, adding that the “vast majority” of data Meta used for training was publicly available as the company wanted to respect privacy concerns. That stipulation does seem to indicate that some of it wasn’t publicly available, although the executive did not elaborate.
Clegg went on to explain that it used public photo and text posts to train its AI. The photos were used to train Emu, the AI that is at the center of the coming AI image editor in Instagram, and text was used to bolster the knowledge of its chat bot.

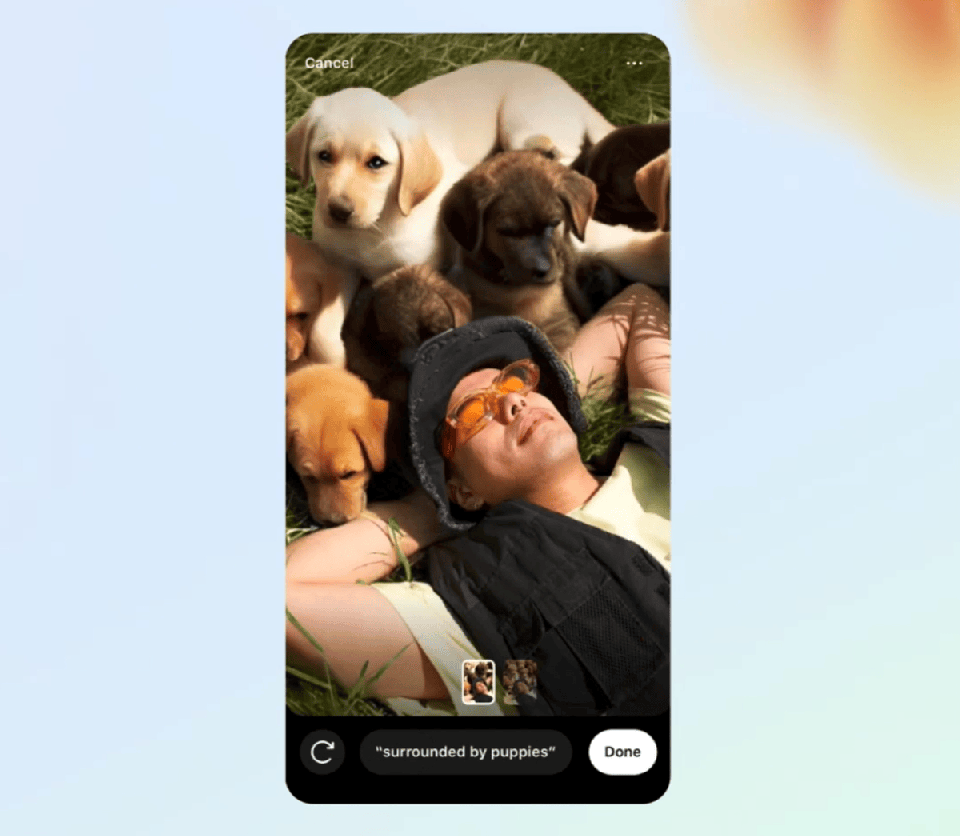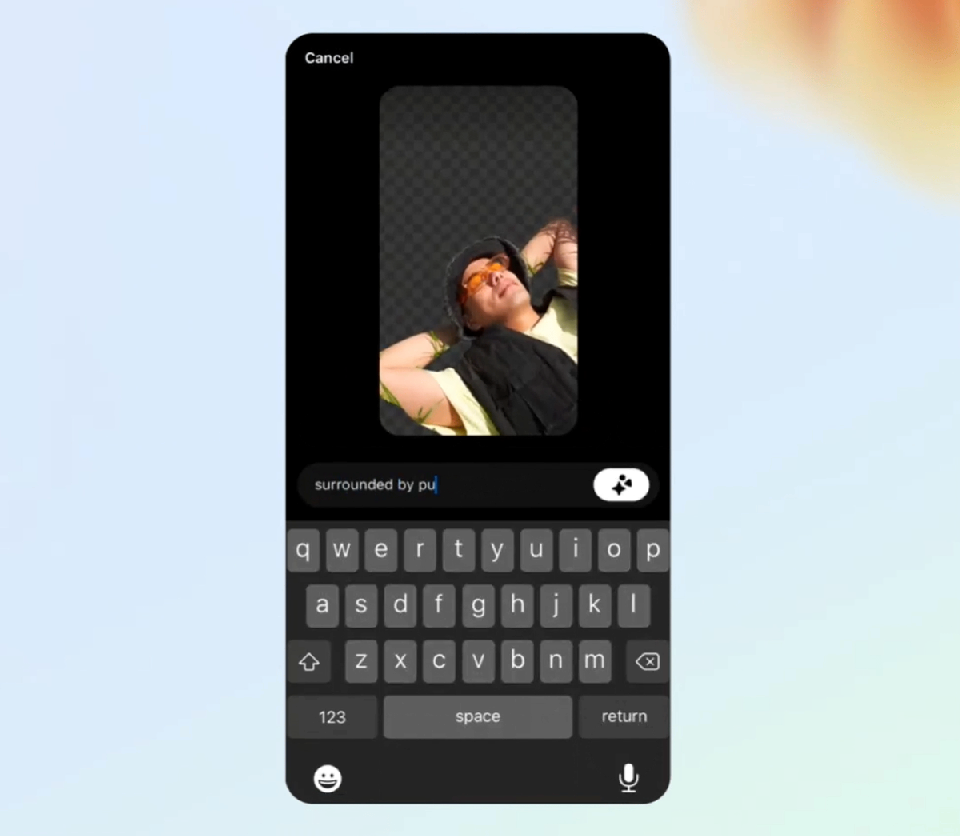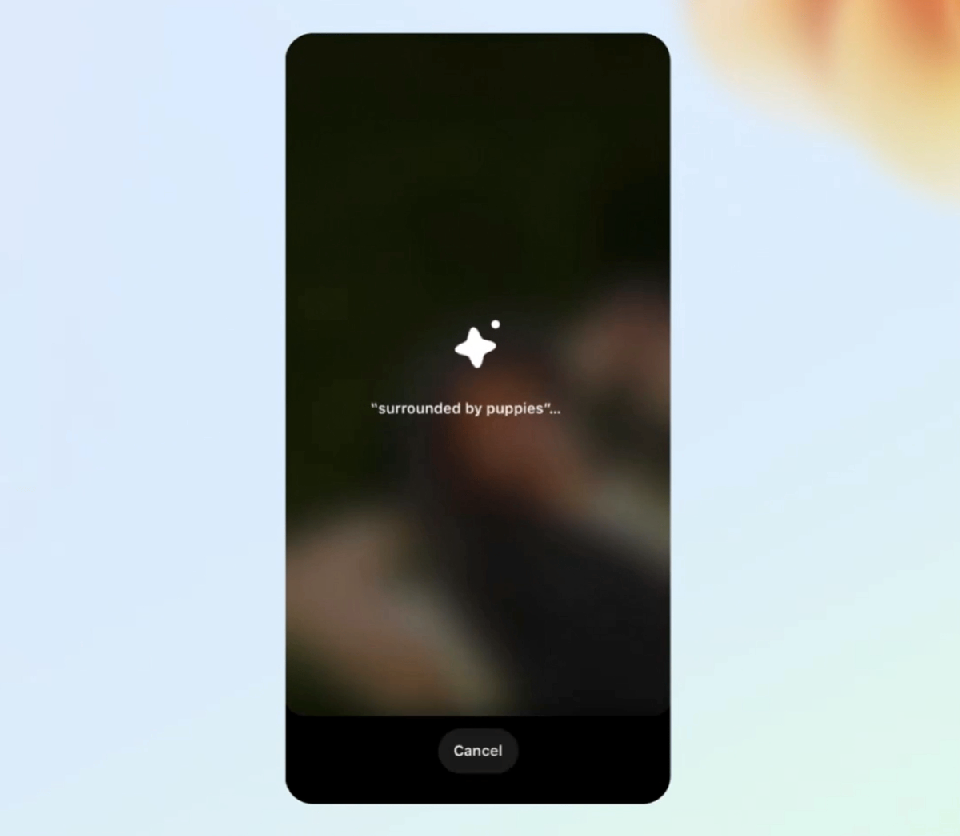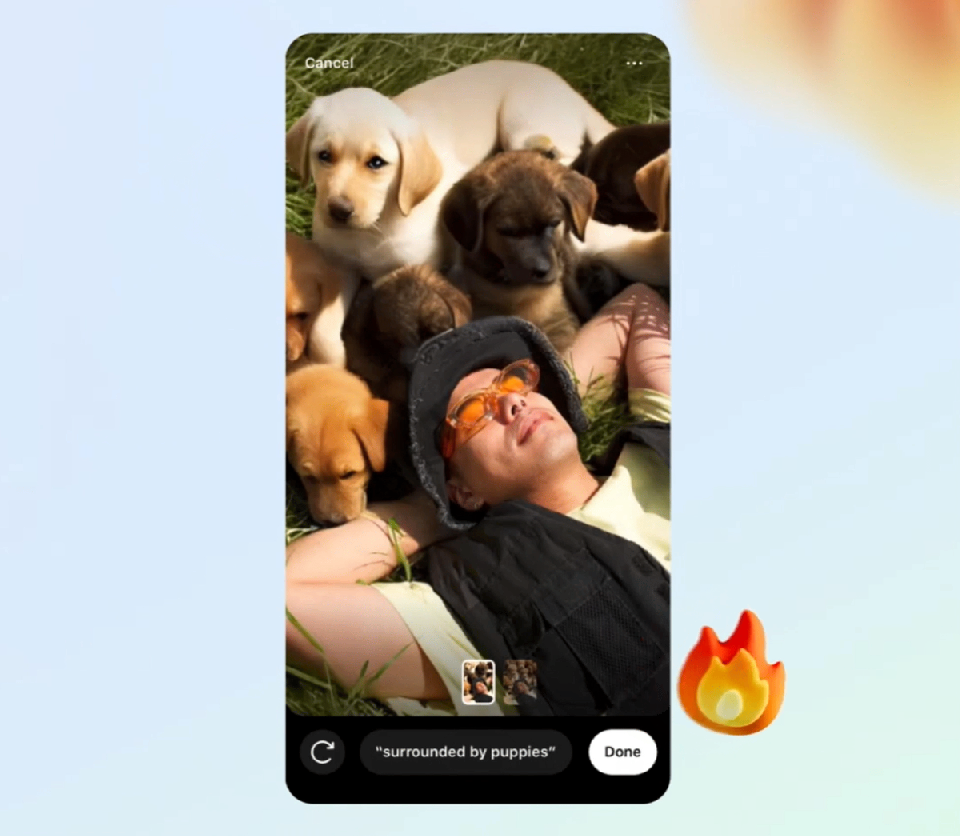
The use of public information to train AI has been a hot topic of discussion for some time now. Clegg touched on it as well, saying that he expects “a fair amount of litigation” to determine whether using copyrighted materials to train an AI is protected by Fair Use.
“Whether creative content is covered or not by existing fair use doctrine… We think it is, but I strongly suspect that’s going to play out in litigation,” he says.
The company doesn’t appear to support using its AI systems to generate copyrighted imagery, and a separate Meta spokesperson tells Reuters that its terms of service bar users from generating content that violates privacy and intellectual property rights.
Image credits: Meta



