Meta Launches ‘Human-Like’ AI Image Generation Model

Meta has announced a “human-like” artificial intelligence (AI) image generation model, I-JEPA, and provided components to researchers. The company says the model will be more effective than generative AI models thanks to relying on background knowledge and context, mimicking typical human cognition.
Reuters reports that I-JEPA “uses background knowledge about the world to fill in missing pieces of images, rather than looking at nearby pixels like other generative AI models.”
In a research post, Meta describes how I-JEPA builds upon Meta’s Chief AI Scientist Yann LeCun’s vision for “more human-like AI.”
“We’re excited to introduce the first AI model based on a key component of LeCun’s vision. This model, the Image Joint Embedding Predictive Architecture (I-JEPA), learns by creating an internal model of the outside world, which compares abstract representations of images (rather than comparing the pixels themselves). I-JEPA delivers strong performance on multiple computer vision tasks, and it’s much more computationally efficient than other widely used computer vision models,” Meta explains.
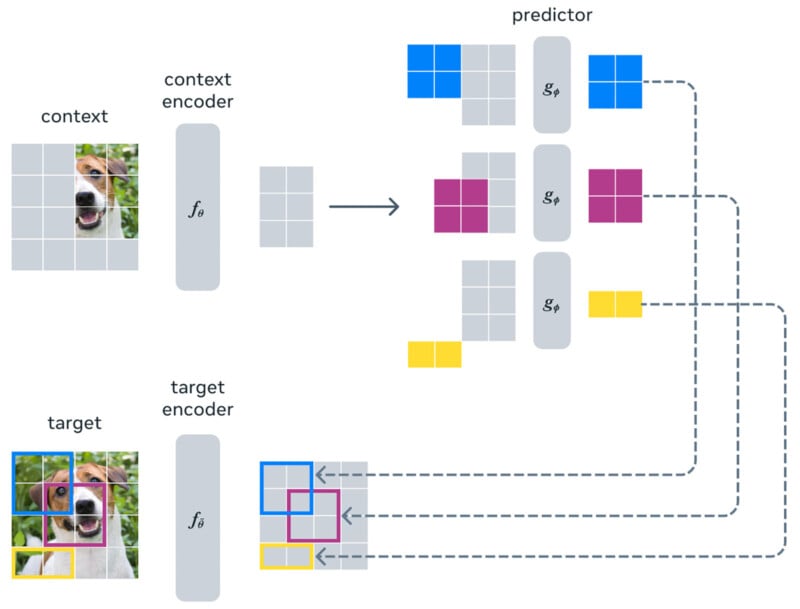
Meta also highlights I-JEPA’s training efficiency, promising that a 632-million parameter visual transformer model can be trained using 16 A100 GPUs in under 72 hours, which the company claims is two to 10 times faster than other methods while delivering fewer errors.
“Our work on I-JEPA (and Joint Embedding Predictive Architecture (JEPA) models more generally) is grounded in the fact that humans learn an enormous amount of background knowledge about the world just by passively observing it. It has been hypothesized that this common sense information is key to enable intelligent behavior such as sample-efficient acquisition of new concepts, grounding, and planning,” Meta says, speaking about the importance of background knowledge within human intelligence.
To effectively incorporate human-like learning into AI algorithms, Meta says that systems must encode common sense background information into a digital representation that an algorithm can access later. Further, Meta says that a system must learn these representations in a self-supervised manner.

“At a high level, the JEPA aims to predict the representation of part of an input (such as an image or piece of text) from the representation of other parts of the same input. Because it does not involve collapsing representations from multiple views/augmentations of an image to a single point, the hope is for the JEPA to avoid the biases and issues associated with another widely used method called invariance-based pretraining,” says Meta.
Meta argues that by “predicting representations at a high level of abstraction rather than predicting pixel values directly,” I-JEPA can “avoid the limitations of generative approaches.”

Some of these limitations are well-documented, including the issues that generative models have with hands. Meta says that these issues arise because generative methods try to fill in “every bit of missing information,” leading to pixel errors humans wouldn’t make. Meta says generative methods focus on “irrelevant details” instead of “capturing high-level predictable concepts.”
“The idea behind I-JEPA is to predict missing information in an abstract representation that’s more akin to the general understanding people have. Compared to generative methods that predict in pixel/token space, I-JEPA uses abstract prediction targets for which unnecessary pixel-level details are potentially eliminated, thereby leading the model to learn more semantic features,” explains Meta.
While Meta’s JEPA models remain in development, Meta has emphasized the importance of sharing components of its AI models with researchers, a move it believes will aid innovation. The full details of JEPA are outlined in a new research paper, which Meta will present at the annual Computer Vision Foundation’s Computer Vision and Pattern Recognition Conference this week.
Image credits: Header photo licensed via Depositphotos.