
Adobe Brings Creative, AI-Powered Express App to the Palm of Your Hand
Adobe has announced its new Adobe Express mobile app is available now to all users.
Adobe has announced its new Adobe Express mobile app is available now to all users.

The 1994 James Cameron film True Lies starring Arnold Schwarzenegger was recently re-released in Ultra HD 4K disc format giving viewers the opportunity to watch these classic films in unprecedented detail.
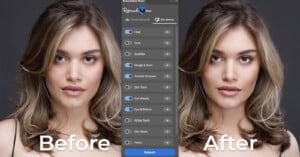
Retouch4me has released an update for its free Adobe Photoshop panel that allows users to edit their images through a single interface with the plugin(s) installed locally or through the cloud, extending its original functionality.

Instagram users may have noticed a new colorful circular logo at the top of their messages interface lately. It is Meta's AI-powered chatbot.
Adobe has previewed generative AI video tools that promise to redefine video creation and production workflows. The tools, designed for Adobe Premiere Pro, enable users to add or remove objects in a scene and will live alongside Adobe's Firefly generative AI models.

In one of her most famous quotes, the photographer Dorothea Lange said that "the camera is an instrument that teaches people how to see without a camera."

Photography website and commerce platform Zenfolio has published its "2024 State of the Photography Industry" report, exploring the changing trends among photographers and their thoughts on significant topics like business and artificial intelligence.

It used to be that if your digital image was too small for a particular application, you had no real options. You were stuck at the original resolution, or at least something close to it. Upscaling technology has changed the game, but not all apps are made equal.

German company Neurapix, known for its artificial intelligence-based software, has released a new feature for its SmartPresets feature, allowing them to be created and used in black and white (B&W) as part of an AI-assisted photo editing workflow.

Tech and software companies working on developing generative artificial intelligence platforms -- and really, who isn't doing that these days -- are in dire need of content to help train their AI models. Adobe is reportedly buying videos to help develop its text-to-video platform now.

Skylum has announced a significant update for its photo editing program Luminar Neo coming this spring that will bring a whole new suite of "next-level" tools as well as an improved user interface (UI).

Dove announced this week a commitment never to use artificial intelligence (AI) in its ads, becoming the first beauty brand to do so.

A new bill introduced by Rep. Adam Schiff would require all AI companies to disclose the copyrighted works used in training sets or face a fine.

It's 2024. Couples with partners of different races and ethnicities should not be an issue. However, it is a problem for Meta's AI image generator, according to a new report and PetaPixel's testing.

Although they held out until now, OnePlus is officially joining the AI revolution. The smartphone company's inaugural AI tool is the AI Eraser, which is a take on Google's Magic Eraser.

Sometimes, artificial intelligence feels so smart it's scary. But when it misses details that should feel obvious, AI feels like it still has a ways to go. Apple's researchers may have found a way to jump over one more hurdle.

New York City Mayor Eric Adams announced the city will trial a new artificial intelligence tool that detects guns.

The machine-learning world just got stupider, and that's a good thing.

Following President Joe Biden's executive order to address artificial intelligence, federal government agencies have until December 1, 2024 to ensure their AI tools "do not endanger the rights and safety of the American people."

Samsung Galaxy AI was introduced alongside the latest Galaxy S24 series smartphones in January, bringing numerous AI-powered features like Circle to Search and Generative Edit to Galaxy devices. Living up to its earlier promise, Samsung says this suite of AI tools will come to more Galaxy devices this week.
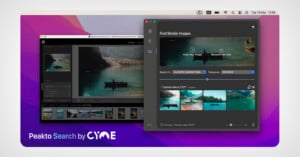
Cyme, the developer behind the AI-powered macOS photo cataloging app Peakto, has announced a new plugin for Adobe Lightroom that enables photographers to search for specific images and videos in their catalog, no matter how big or disorganized.

The world's most famous photographer Annie Leibovitz says she's not worried about artificial intelligence (AI) and that photography itself isn't real.

As Apple continually reaffirms its commitment to developing artificial intelligence (AI), the Cupertino tech giant is reportedly in talks with Google to build its Gemini AI engine into the iPhone.

The companies developing generative AI technologies are, typically, skirting around the rules regarding copyright: very few actually provide the public with concrete information on how they train their models.

After European Union lawmakers reached an agreement on the EU's landmark EU AI Act in December, the law cleared its last significant hurdle, achieving European Parliament approval earlier today.

Computational photography techniques are the backbone of what makes smartphone cameras as good as they are and for years, photographers have been wondering when that technology would arrive in standalone cameras.

Sight was the first of our senses to be technologically shared in a world we did not witness with our own eyes. Photography—writing with light—has historically meant a one-to-one relationship between what was before a camera (defined as a lens focussing light on a recording media) and what came out the other end, created by a human.

Artificial intelligence companies Stability AI and Midjourney Inc. are fierce competitors in the AI image generation space. The rivalry has allegedly boiled over into the dangerous and felonious realm of corporate espionage.
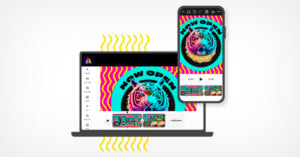
Adobe released a beta version of its new Express mobile app for Android and iOS devices which also introduces the company's Firefly generative AI technology into mobile content creation and editing workflows.

Shane Jones, a Microsoft Engineer who worked for the company for six years, has written a letter to the FTC to warn that the CoPilot AI ignores copyrights and is capable of creating violent, sexual images that "sickened" him.

DxO has announced the 4.0 Update to PureRAW which adds a new and improved generation of its Denoising AI, improved workflows, and sets a new industry standard for RAW image quality enhancements.
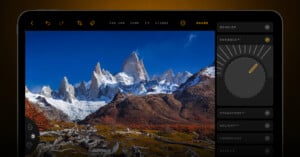
Skylum is bringing Luminar to the Apple iPad through its first official app that also works in Vision Pro.

Apple appeared content to sit by the sidelines as the AI craze took the tech world by storm last year, but that has changed. Apple is all in on AI, and it seemingly happened in the blink of an eye.

Chinese multinational Alibaba, best known for its e-commerce operations, also heavily invests in technological development projects. Researchers in the company's Institute for Intelligent Computing showed off their new AI video generator, EMO.

A new advanced neuromorphic system designed to eliminate blurring in smartphone photos is now ready for production, using a mix of AI and existing processing power to freeze action in ways not seen on current smartphones.
Two pieces of interesting artificial intelligence (AI) news came out of Apple's annual shareholder meeting today, and both tip Apple's hand a bit regarding generative AI technology.

A child's online privacy has long been a concern for parents and guardians, and even law enforcement. It is a topic mired in debate, and it's also an ever-changing technological landscape thanks to new AI tools. Wading into the complicated situation is freelance writer Hannah Nwoko in a new piece for The Guardian.

Adobe Research revealed a new generative AI music and audio prototype, Project Music GenAI Control, that promises to give anyone the power to create music, no matter their experience or skill.
As cameras get faster and storage gets cheaper, it is all too easy for photographers to shoot everything, delete nothing, and find themselves struggling in an endless sea of photos. That's where Peakto's new centralized deletion feature comes in.

An analog photographer has stuck his head above the parapet to claim that AI-generated images are "the best thing that has happened to photography."